




Qgis 2. - Data analyse
the workshop starts here
Deze workshop neemt je mee om de eerste stappen te zetten in het rekenen met geodata. We gaan kijken hoe we nieuwe data kunnen genereren door selecties te maken, datasets te koppelen en kleine berekeningen te doen. Deze workshop gaat er vanuit dat je de workshop Qgis 1. - Setting up hebt voltooid.
Deze workshop is gemaakt op Qgis versie: 3.14.16-PI
Geospatial analysis
Er zijn heel veel mogelijkheden om berekeningen te doen in Qgis.
-
We beginnen met een selectie maken.
-
deze selectie kunnen we vervolgens exporteren om een nieuwe (subset) dataset te maken.
-
We kunnen tabellen koppelen aan elkaar.
-
Statistieken opvragen en samenvattingen genereren.
Selecteren
Er zijn een aantal manieren om de data te selecteren:
- Select by hand
- Select by data
- Select by location
by hand betekend zelf een selectie tekenen met de muis. Select by data dan gebruiken we de data om een bepaalde selectie te maken, bijvoorbeeld: Selecteer alle gebieden met het gewas; gras. Select by location betekend dat we de locatie van de data(of een andere dataset ) pakken om een selectie te maken, bijvoorbeeld: Selecteer de gebieden die overlappen met de punt data.
We gaan ze hier kort uitproberen.
Select by hand
Kies in de werkbalk boven aan de Select Features by Polygon tool
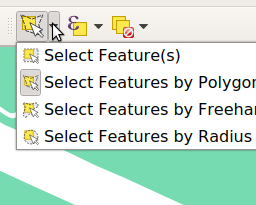
Er zijn 4 mogelijkheden, selecteren door te klikken, een polygoon te tekenen, een rondje te tekenen of een freehand polygoon.
Teken door te klikken een polygoon om de velden heen die je wilt selecteren. (rechter klik om het af te ronden)
Nu hebben we een eigen selectie gemaakt! Wil je het nog een beetje aanpassen? Kies de bovenste optie : Select Feature(s) en houdt de Shift knop ingedrukt. Klik nu op het perceel wat je toe wilt voegen of weg wilt halen!
Select by data
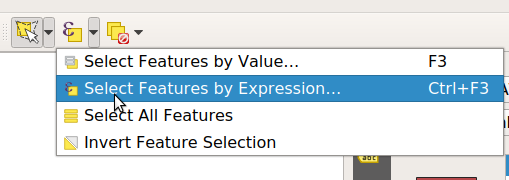
Een andere manier van selecteren is om de data te gebruiken. Hiervoor gebruiken we de Select Features By Expresion... tool.
Open de tool door in de werkbalk de knop aan te klikken. Er opent zich nu een nieuw veld.
Dit is de Expression builder. Dit scherm, met dit format gaan we vaker tegen komen. Het is een ontzettend handige tool om de data te manipuleren maar het vergt even inzicht in hoe je een expressie opbouwt.
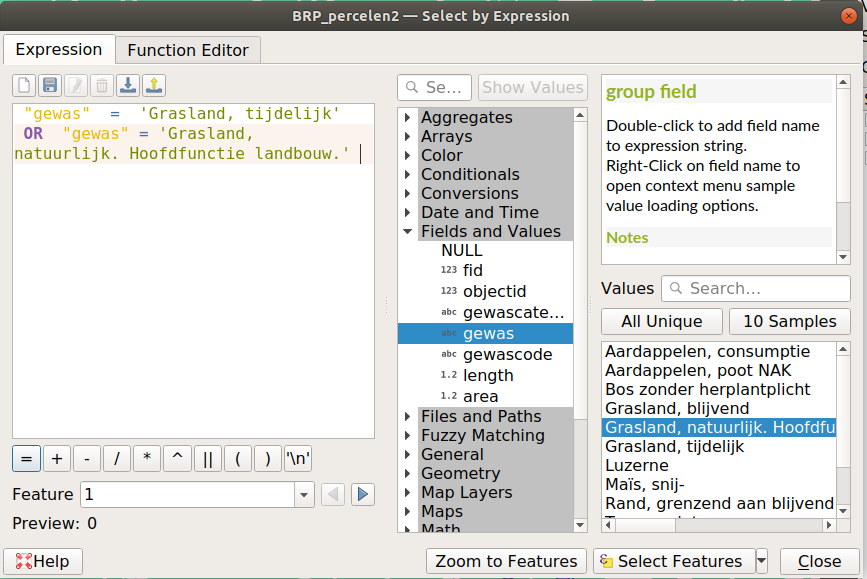
De expressie die je invoert in het linker veld, wordt per feature gevalideerd. Voldoet een feature aan de expressie dan wordt deze geselecteerd, voldoet deze niet, dan wordt het niet geselecteerd. We beginnen met een simpele expressie:
"gewas" = 'Grasland, tijdelijk'
Het middelste veld geeft je elementen die je kan gebruiken in de expressie. Klap de Fields and Values naar beneden.
Hier zie je de attributen die beschikbaar zijn om een expressie mee te maken.
Kies gewas door dubbel te klikken op het attribuut.
Voeg dan een = teken toe door erop te klikken of in te typen.
Toen je op “gewas” klikte ontstond er rechts meer informatie.
Klik op 10 Samples
We krijgen nu 10 mogelijke waarden van het attribuut “gewas” te zien! Zo kunnen we ze snel in onze expressie krijgen en we maken geen typefouten:
Dubbel klik op een gewas soort in het meest rechter veld. Nu staat het in de expressie.
Klik op Select Features
Zie je ze geel oplichten?
Sluit het vorige venster en verwijder de selectie.
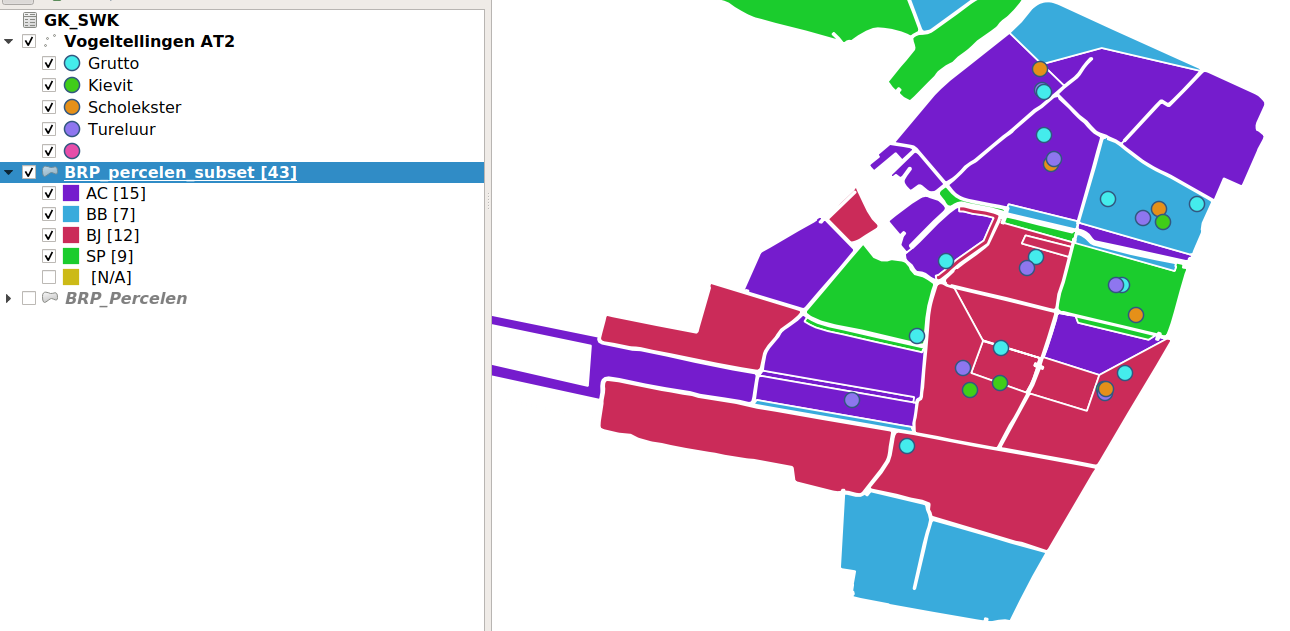
Select by location
Zoals de naam al zegt, gaan we selecteren met gebruik van de locatie! Hiervoor zijn altijd 2 datasets nodig. De eerste waaruit je wilt selecteren. Van de tweede dataset wordt de locatie gebruikt om de selectie te maken.
Zo kunnen we snel alle velden selecteren waar een telling is gedaan!
Ga naar het menu Vector > Research Tools > Select by location
Er opent zich weer een nieuw scherm.
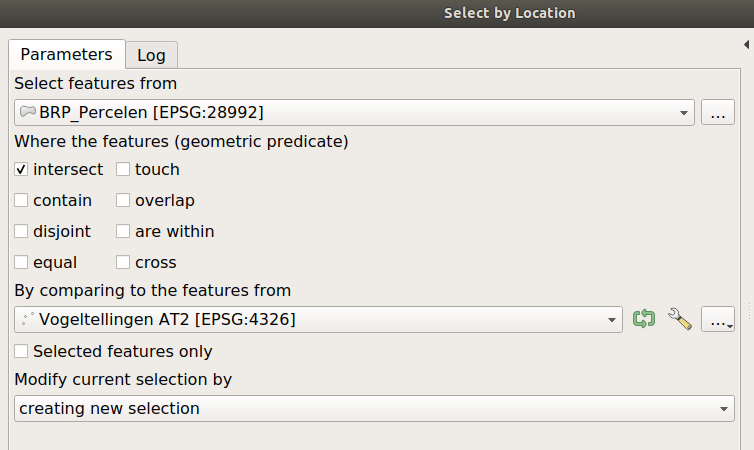
De bovenste dataset geeft aan waaruit we willen selecteren. Zet deze op de BRP percelen.
Vergelijk ze met de vogeltellingen punten.
Hoe verhoud de locatie zich tot elkaar?
- Intersect - A en B delen enige ruimtelijke plaats >
1,2,3- Contain - A bevat B compleet.
no circle selected(tegenovergestelde van Are Within) Als je de selectie zou omdraaien > wordt het vierkant wel geselecteerd omdat deze compleet cirkel 1 bevat.- Disjoint - A en B delen niets >
4- Equal - A en B hetzelfde >
no circle- Touch - Aanraken maar niet overlappen >
3- Overlap - Overlappen maar niet kompleet >
2- Are Within A compleet in B >
1(tegenovergestelde van Contain)- Cross - lijnen kruising
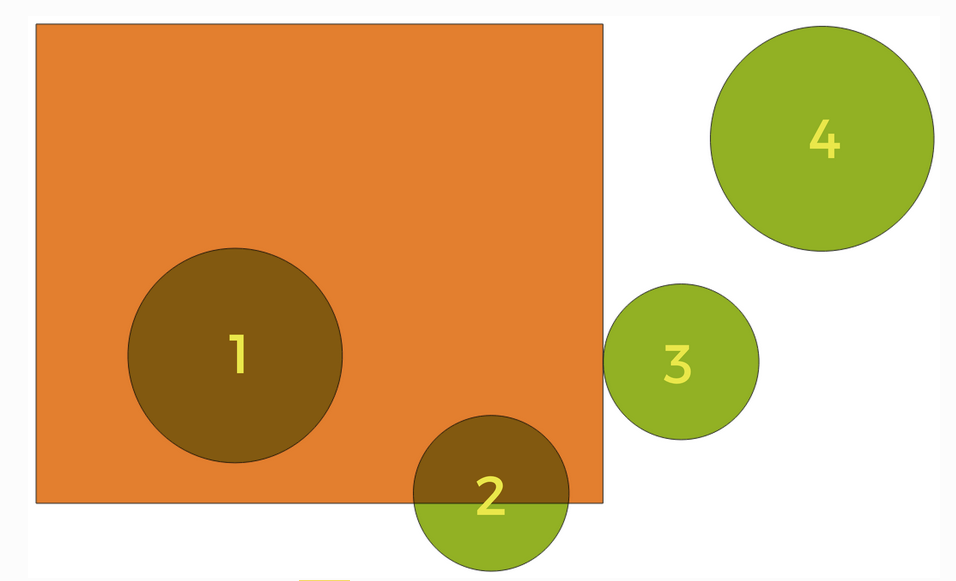
Kies de juiste instellingen en klik op Oké. Lukt het je om alle percelen te selecteren waar een vogel telling is gedaan?
Opslaan Subset
Om onze selectie tot echte subset te maken gaan we de data simpelweg opnieuw opslaan!
Selecteer de percelen die jij wilt hebben, op jou gekozen manier. We gaan aan de slag met de vogeltelling. Dus neem in ieder geval de percelen met vogeltellingen erop!
Als je jouw percelen hebt geselecteerd: Rechtermuisklik op de BRP gewaspercelen laag. Export > Save Selected Features As..
Sla de data op als Geopackage in jouw 📂 werkfolder met CRS EPSG:28992
Zorg dat het vinkje onderaan Add saved file to Map is aangevinkt. Dan krijgen we onze nieuwe dataset meteen te zien!
Helaas is onze symbology stijl wel verdwenen. Voordat je de oude BRP laag weg haalt, kunnen we eerst de stijl kopiëren.
Rechtermuisklik op de BRP percelen laag > Styles > Copy Style > Symbology
Nu Rechtermuisklik op de nieuwe subset BRP percelen laag > Styles > Paste Style > Symbology
.. en voila! Zet de oude BRP percelen laag uit.
Join
In de tabel GK_SWK hebben we informatie staan die we aan de BRP percelen willen koppelen. Gelukkig hebben ze allebei een lijst met de object IDs van de BRP percelen.
Let op! Het
fidveld is een automatisch gegenereerd, arbitrair veld, wat intern door Qgis(of een ander gis programma) wordt aangemaakt om unieke volg nummers te creëren. Gebruik deze echter nooit voor identificatie! Want het zegt niks over het perceel. De BRPobjectidis een administratieve code die samenhangt met de gewas informatie. Dit is de identificatie die je wilt gebruiken om veranderingen door de jaren heen te waarborgen.
Rechtermuisklik op de BRP gewassen subset layer. Kies Properties
Ga naar het tabblad Joins
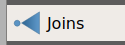
Voeg een nieuwe join toe door op de groene plus te klikken. Er opent zich een nieuw venster.
We willen de tabel GK_SWK koppelen. Kies deze en zet de velden waarmee beide tabellen gekoppeld moeten worden op de juiste attributen.
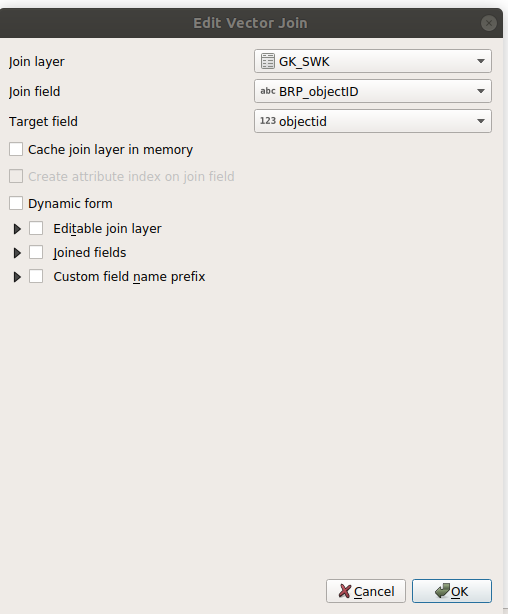
Klik op OK
Is er iets veranderd? We zien nog niks..
Dit komt omdat alleen de attribuut data gekoppeld is aan elkaar. Open de attribuut tabel van de BRP percelen. Zie je de extra data die er bij is gekomen in de tabel?
Laten we het meteen gaan gebruiken! Sluit de attribuut tabel.
In de Layer Styling visualiseer de data op Categorized en kies een nieuw attribuut die nu beschikbaar is van de GK_SKW dataset: Bedrijf.
Klik opnieuw op Classify
Nu zijn onze percelen gekleurd op bedrijf!
Provide Feature Filter - Query Builder
We willen nu ook de vogel tellingen combineren met onze percelen. Maar voordat we dat doen gaan we de vogeltellingen eerst filteren. We willen namelijk alleen kijken naar monitor moment 4. In plaats van een definitieve subset te maken, maken we alleen een filter van toepassing binnen dit project.
Rechtermuisklik op de laag vogeltellingen > Rename layer
Verander de naam in vogeltellingen monitormoment 4
De rename veranderd niks aan onze dataset! Open de properties maar en zie dat de laag nog steeds naar de vogeltellingen punten dataset verwijst in onze 📂 werkfolder.
We gaan nu een filter op de laag zetten:
Rechtermuisklik > Properties Ga naar tabblad Source
Hier kan je onder Provide Feature Filter een filter geven die geldt voor de hele laag! Het maakt een subset van de dataset gebaseerd op de expressie.
open de Query Builder
De expressie is de filter voor deze laag:
"monitormoment" = 4
Klik op Test en vervolgens op OK
Nu zien we alleen de vogeltellingen punten uit monitor moment 4. Alle berekeningen en visualisaties die we nu doen op deze laag gebruikt alleen de subset monitor moment 4. Hoewel de data niet veranderd is en we ook geen nieuwe dataset hebben hoeven aanmaken.
Achter de vogeltellingen laag zie je nu ook een “trechter” staan. Zo kun je zien dat er een filter op die laag zit.
Join Attributes by Location (summary)
Nu gaan we de vogel tellingen combineren met onze percelen. Hoe doen we dit? De vogel tellingen bevatten geen perceel id.. Maar we hebben natuurlijk de locatie!
We willen het aantal vogels per perceel weten. Maar een perceel kan meerdere vogeltellingen bevatten. Hoe kunnen we deze dan koppelen? Als we de tool Join Attributes by Location zouden gebruiken, dan krijg je de output zoals in de bovenste 2 tablellen. Meerdere records per perceel, of per punt een perceelID.. Het maakt niet uit welke kant uit de join gedaan wordt. Dit zijn one-to-one koppelingen en hier helemaal niet handig. Je krijgt altijd een dataset die per perceel meerdere records gaat hebben, en dat willen we niet!
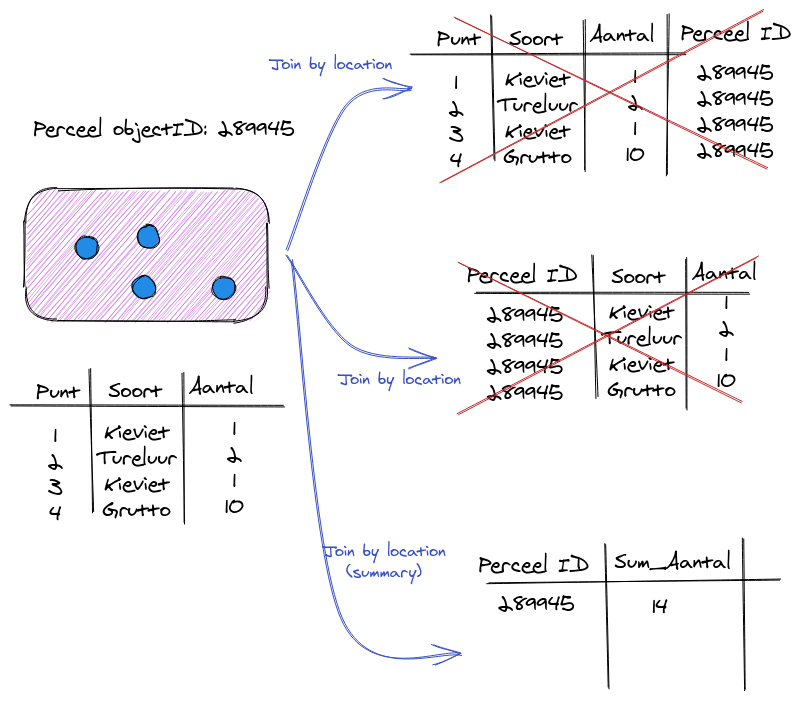
Het onderste geval, het aantal vogels per perceel (zonder dubbel) is een many-to-one koppeling of een aggregate. We moeten wat met de vogelteldata aggregeren om per perceel extra informatie te krijgen. Dit doen we met de tool Join attributes by location (summary)
Wat gaan we doen?
Per perceel gaan we kijken welke punten er op liggen (join Attributes by location) en dan gaan we de SUM pakken van het veld Aantal waardoor deze netjes bij elkaar op worden geteld en wij het aantal vogels per perceel krijgen.
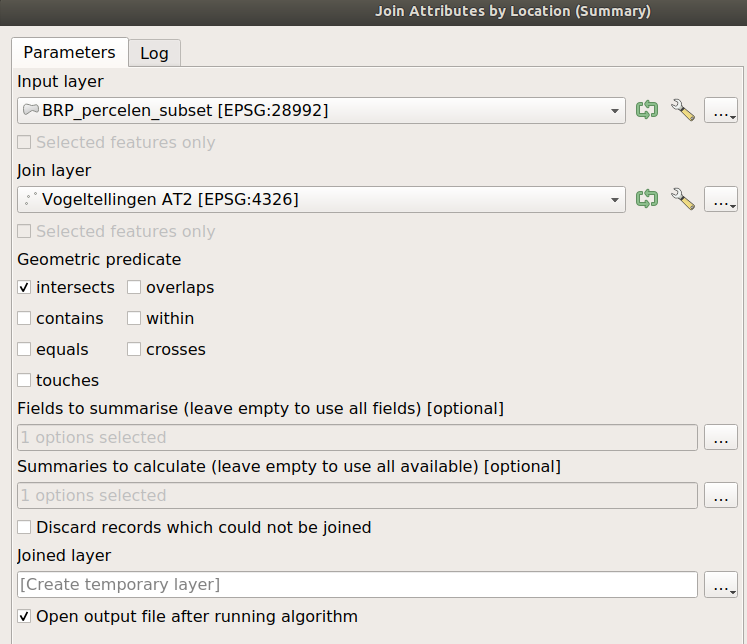
Zoek in de zoekbalk naar de tool > Join attributes by location (summary)
We willen het aantal vogels per perceel weten. Dus de BRP percelen subset is onze Input Layer en de vogeltellingen onze Join Layer Stel dit in.
Bij Fields to summarise kiezen we alleen het veld aantal en soort_code Stel dit in door op de ... te klikken en het veld aan te vinken en dan op OK .
Dit zijn de velden van de vogeltellingen die samengevoegd(aggregated) gaan worden.
Bij Summaries to calculate kiezen we sum zodat we de optel som van de waarden krijgen en unique zodat we het aantal unieke voorkomens krijgen Doe dit door op de ... te klikken en het veld aan te vinken.
We kunnen zelfs nog meer statistieken mee nemen, bijvoorbeeld min en max. Probeer je te bedenken wat de output zou zijn van deze statistieken?
Run de tool.
Nu hebben we het totaal aantal vogels per perceel uitgerekend!
De tool creëert een tijdelijke nieuwe laag waar deze informatie in zit. Het veranderd dus niks aan onze originele data. Maar als we deze tijdelijke laag niet op slaan dan gaat deze dataset verloren bij het afsluiten van Qgis… We maken eerst nog wat aanpassingen en dan slaan we de dataset op.
Open de attribuut tabel van de nieuwe dataset.
Het attribuut heet aantal_sum bevat het totaal aantal vogels dat voorkomt in een perceel. Het bevat ook erg veel NULL waarden waar een perceel geen vogeltelling bevat. Dit is erg lastig om de data mee te stijlen. We willen namelijk liever dat er de waarde 0 wordt meegegeven, wat gelijk staat aan 0 aantal vogels.
De tabel bevat ook een attribuut soort_code_unique, dit is het aantal unieke soorten wat voorkomt in een perceel. Het attribuut aantal_unique bevat eigenlijk precies hetzelfde.
Attribuut tabel - kolom aanpassen
We gaan de attribuut tabel wat mooier maken.
Open de attribuut tabel van de nieuwe tijdelijke laag die je net gemaakt hebt.
In de tabel ga in edit mode, door op het  te klikken.
te klikken.
Edit mode
Let op! Als je de edit mode aanzet betekend het dat je echt daadwerkelijk wat gaat veranderen aan de bestaande dataset! Ben hier dus heel voorzichtig mee. Zet het aan wanneer je het nodig hebt en meteen weer uit als je klaar bent!
Als je in edit mode bent kan je handmatig de waarden in de tabel aanpassen. Maar de naam van een attribuut veranderen, een attribuut toevoegen of verwijderen gaat niet zomaar. We beginnen met een attribuut updaten.
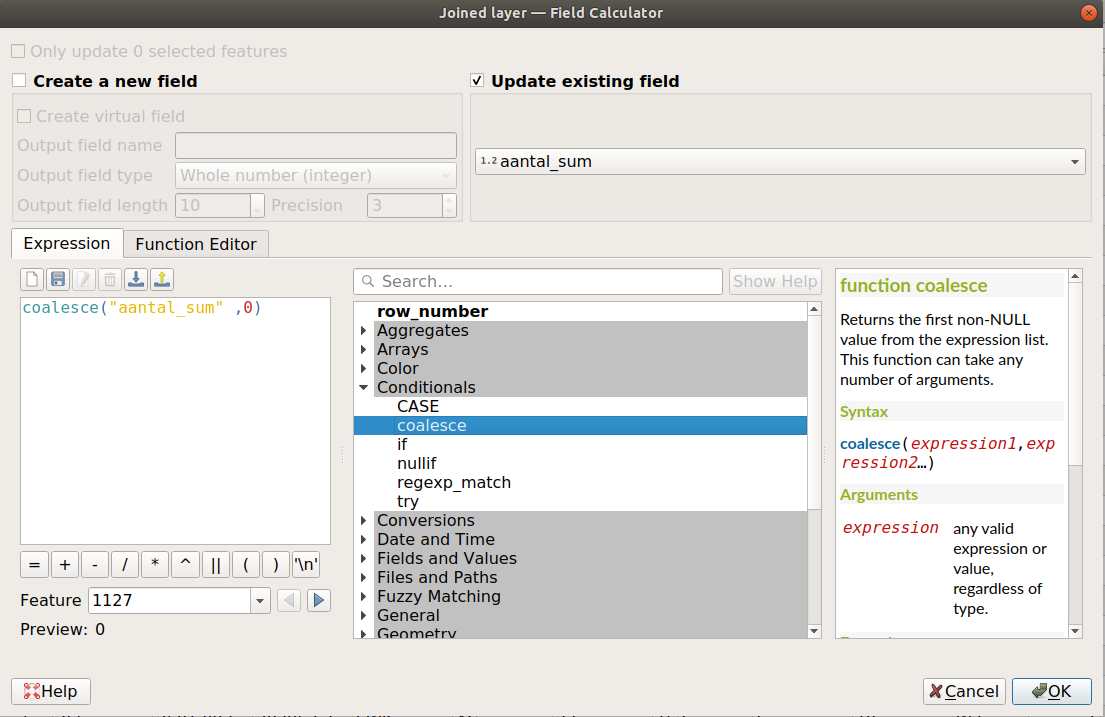
Open de Field Calculator

Kies voor Update existing field en kies het veld aantal_sum
In de expression vlak vul in :
coalesce("aantal_sum" ,0)
De coalesce expressie geeft de eerste niet-NULL waarde terug die het tegenkomt in de input lijst.
We updaten het veld aantal_sum dus met zichzelf, en als het een waarde bevat dan houd het die waarde. Heeft het een NULL waarde dan krijgt het nu een 0 waarde.
Druk op OK
Zie je dat de NULL waarden in de kolom zijn vervangen voor 0?
Doe hetzelfde voor de kolom soort_code_unique
Sla de edits op!
Attribuut tabel - kolom verwijderen
Er zijn een aantal kolommen die we helemaal niet nodig hebben. Deze gaan we eerst opruimen.
Kies de knop Delete fields

Gooi de kolom aantal_unique weg.
Save de edits door deze op te slaan

Attribuut tabel - nieuw attribuut
Open nogmaals de Field Calculator
Maak nu een nieuw veld aan met de naam vogles_per_m3
We gaan het gemiddeld aantal vogels per vierkante meter uitrekenen!
Omdat dit waarschijnlijk geen mooi rond nummer word zetten we de Output field type op Decimal number (real) met een precisie van 5.(het zijn nogal kleine waarden)
In het expressie veld gaan we het aantal vogels delen door het aantal vierkante meter oppervlakte. Lukt het je deze functie zelf samen te stellen?
Het antwoord staat hier > “aantal_sum” / “area” < selecteer de regel
Save de edits door deze op te slaan
Zet de editing uit! Door nogmaals op de edit knop te klikken
Make permanent
Nu hebben we onze dataset aangepast. Het is echter nog steeds een tijdelijke laag. Zie het  tekentje achter onze layer. Dus als we tevreden zijn met het resultaat, sla het dan netjes op.
tekentje achter onze layer. Dus als we tevreden zijn met het resultaat, sla het dan netjes op.
Rechtermuisknop op de tijdelijke laag > Make permanent.... Sla de laag op als Percelen_beheer_vogels_m4 in de 📂 werkfolder. Format = geopackage.
Voeg de nieuwe dataset toe aan het project en pas de styling zo aan zodat de velden een kleur krijgen naar de hoeveelheid vogels!
Analyse Flow
Het is altijd handig om de analyse die je wilt doen eerst uit te tekenen. Zo kun je goed nadenken over welke stappen je moet nemen in Qgis. Vooral als de analyse inhoud dat je meerdere tijdelijke lagen gaat creëeren totdat je bij het juiste eind resultaat bent gekomen!
We willen meer weten over het aantal vogels per soort per perceel.
De tools Join Attributes by Location en Join Attributes by Location (summary) zijn hier beide geen uitkomst voor.
Want we willen per perceel weten hoeveel Kievieten, tureluurs, Gruttos en Fuuten zijn. Omdat de soorten zijn aangegeven als 1 eigenschap kan de tool Join Attributes by Location (summary) nooit een samenvatting geven per soort opgesplitst.
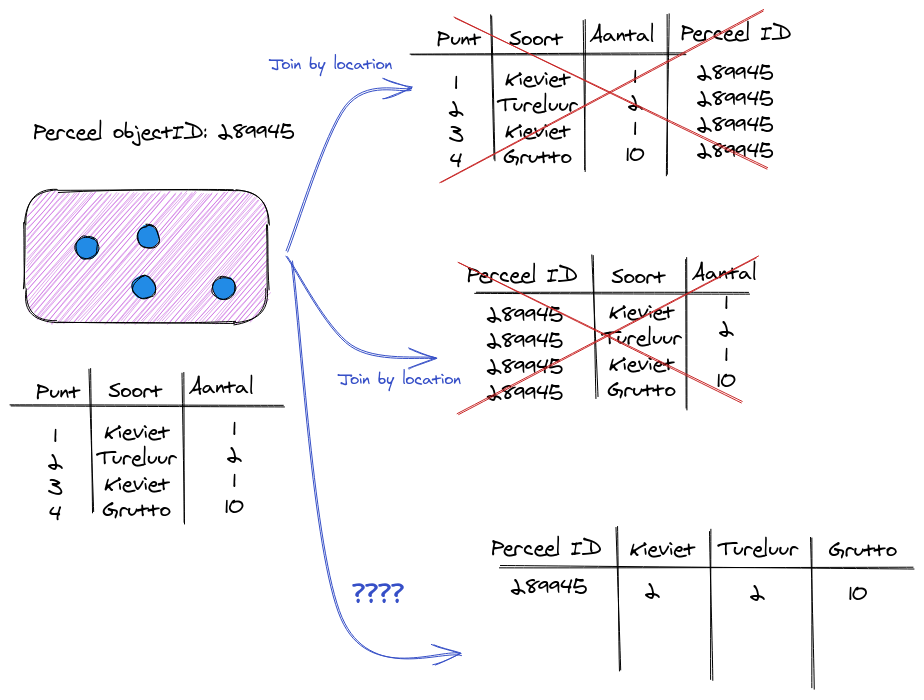
Dus hoe komen we daar? Er zijn 2 manieren en beide hebben meerdere stappen nodig.
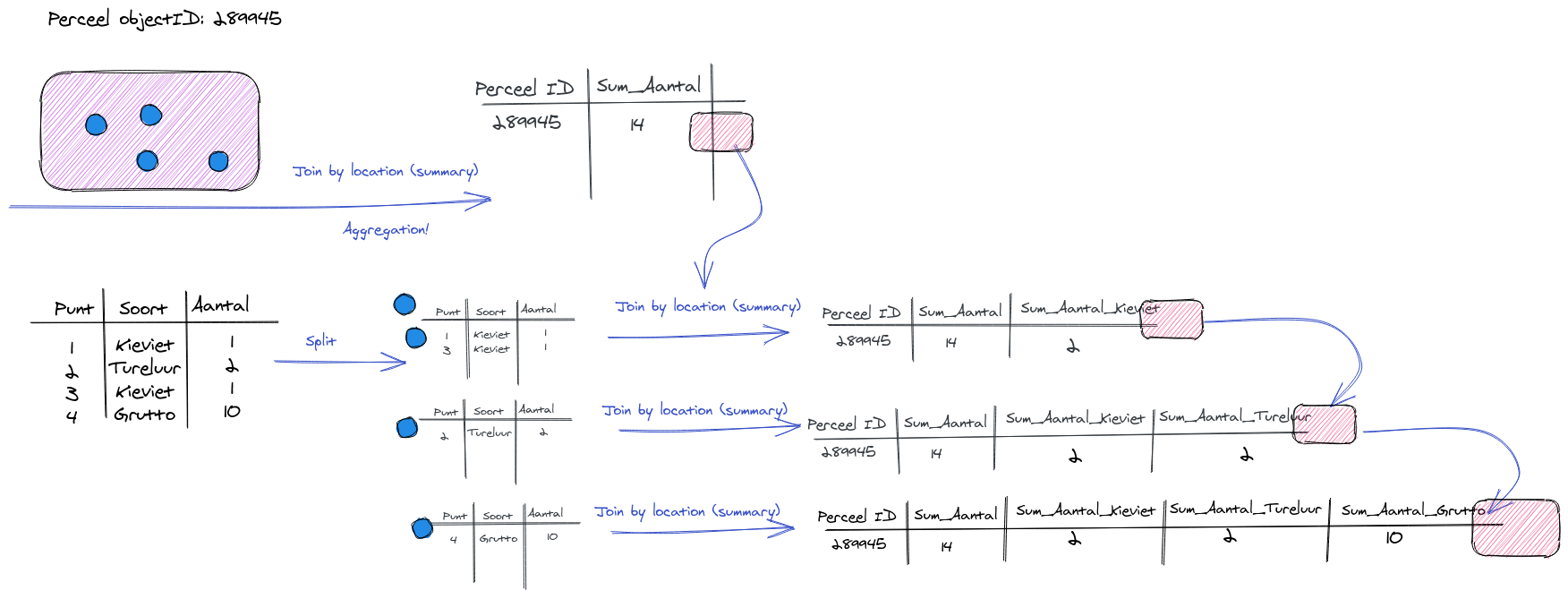
De eerste methode houd in dat we de vogeltellingen laag gaan opspliten in 4 lagen. 1 laag per soort. en dan elke laag weer gaan koppelen aan de percelen dataset doormiddel van de Join Attributes By location (summary). Dit moeten we dus 4 keer doen en het produceert elke keer een nieuwe dataset die weer de input is voor de volgende.
Split Vector layerJoin Attributes By location (summary)Join Attributes By location (summary)Join Attributes By location (summary)Join Attributes By location (summary)
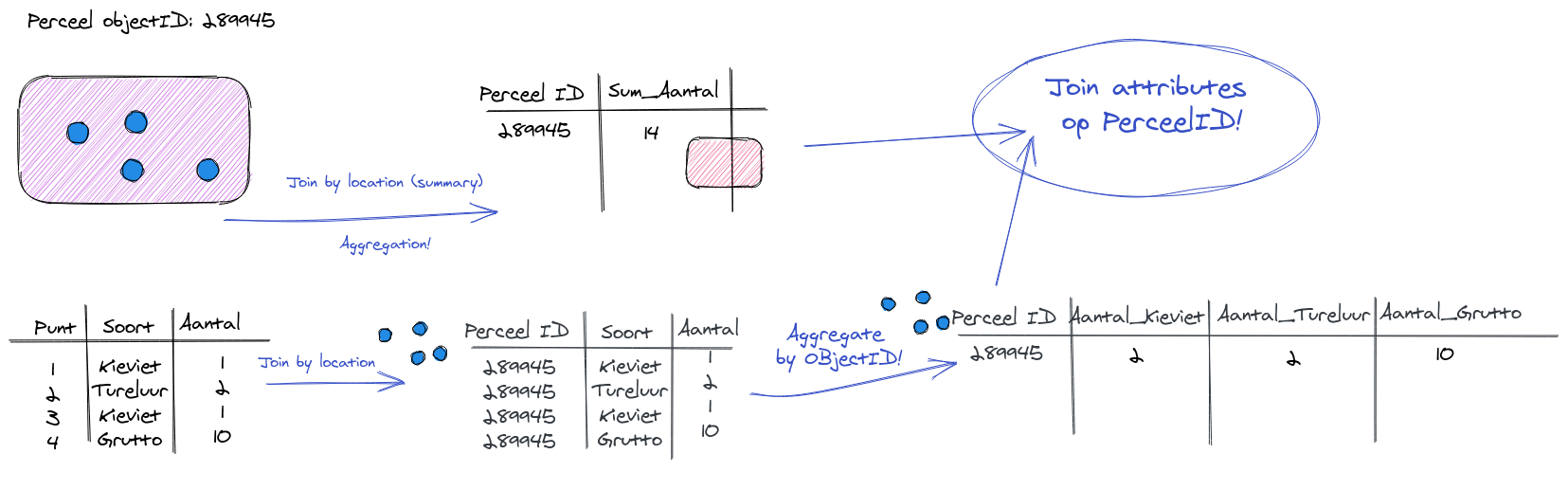
De tweede methode is een Aggregate maken. Dit ziet er eerst wat lastiger uit maar is uiteindelijk sneller en makkelijker!
We doen eerst een Join Attributes by Location met als target de vogeltellingen punten, zo krijgen we per punt een perceel objectID. Op deze tabel gaan we een Aggregate maken met als aggregatie niveau de objectID. Zo krijgen we per objectID een samenvatting die wij willen van de vogeltellingen. Vervolgens kunnen we de aggregatie tabel die we hebben weer makkelijk koppelen aan de percelen door een Join te doen op attribuut niveau.
Join Attributes by LocationAggregateJoin
We gaan beide methoden in de volgende stappen uitleggen en uitvoeren:
Split Vector Layer
We gaan 4 lagen maken! Per vogel soort, een laag. (We gaan dit sowieso doen en bewaren omdat het later ook interesant is voor de visualisatie)
In het menu ga naar Vector >Data Management tools > Split vector layer
Dit opent een nieuw venster
Kies als input Layer de vogeltellingen van monitor moment 4.
Om te splitsen op soort kiezen we soort_code als Unique ID field
Zet de output file type op gpkg (GeoPackage)
Kies jouw 📂 werkfolder als Output directory. Hier worden de nieuwe datasets opgeslagen.
Run de tool
De data wordt niet vanzelf toegevoegd aan het project. In de Browser kun je onder Home directory de 4 nieuwe datasets vinden:
- soort_code_1.gpkg
- soort_code_2.gpkg
- soort_code_3.gpkg
- soort_code_4.gpkg
Natuurlijk hebben we 4 nieuwe datasets want er komen 4 unieke vogel soorten voor in de vogeltellingen dataset.
Voeg de 4 datasets toe aan het project en geef ze een bijpassende layer naam. Rechtermuisklik > Rename layer
Nu hebben we dit gedaan:
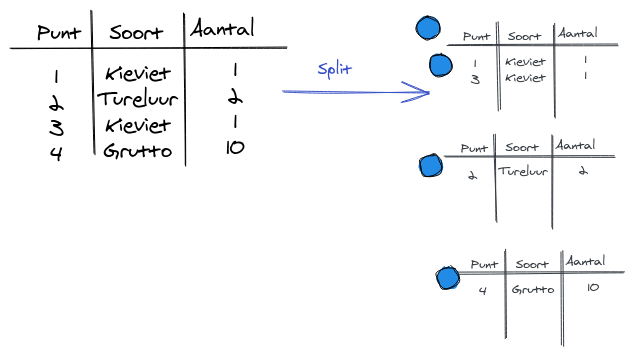
Kijk of je nu zelf de volgende stappen kan afmaken van de analyse om tot het gewenste eind resultaat te komen: Per perceel het aantal vogels per soort

methode:
Elke vogel soort laag koppelen aan de percelen dataset doormiddel van de Join Attributes By location (summary). Dit moeten we dus 4 keer doen en het produceert elke keer een nieuwe dataset die weer de input is voor de volgende.
Join Attributes By location (summary)Join Attributes By location (summary)Join Attributes By location (summary)Join Attributes By location (summary)
Kijk voor hulp terug naar de stap Summary by location
Sla het eind resultaat netjes op en gooi de tussentijdse lagen weg. Zie ook het stukje Verwijderen lagen
Join Attributes by location
Voor de tweede methode gaan we wel de Join Attributes by location uitvoeren. Dit geeft geen nuttige dataset, maar is wel een nuttige input voor de volgende stap!
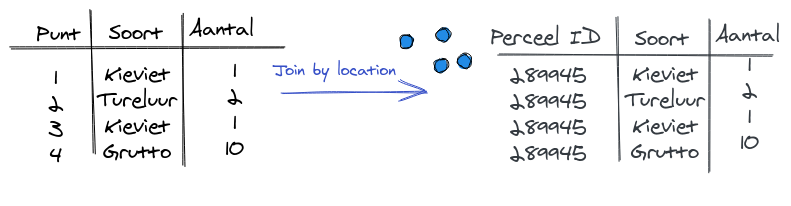
Ga naar het menu Vector > Data Management Tools > Join Attributes by location
De Base Layer is de vogeltellingen monitor moment 4
De Join Layer zijn de percelen.
We hoeven alleen de objectIDs te weten.
Bij Fields to add vink alleen de objectid aan.
Vink de Discard records which could not be joined aan.
Run de tool
Kijk eens in de attribuut tabel van de nieuwe dataset. Klopt het? Zie je de waarden van de object ids meerdere keren voor kunnen komen? We hoeven deze dataset niet op te slaan. Het is een tussentijds product. Straks kunnen we deze gewoon weg gooien.
Aggregate

Zoek de tool in de zoekbalk Aggregate . Lees de beschrijving eens door.
We gaan de vorige tijdelijke joined layer gebruiken als input.
Kies de juiste laag bij input layer
Het aggregatie niveau is het objectId, want we willen een samenvatting van de vogelteldata per perceel.
Group by expression zet deze op objectid
De volgende stap is wat gecompliceerder. In de Aggregates tabel kunnen we de nieuwe velden gaan aanmaken die we willen hebben. Hier kan je ook Expressies op doen en een Aggregate Functie kiezen. Daarnaast is het belangrijk het veld een goede naam te geven en het juiste Type data te kiezen.
Verwijder alle bestaande velden.
Maak de volgende nieuwe velden aan:
| Source Expression | Aggregate function | Name | Type | Length |
|---|---|---|---|---|
objectid |
first value |
objectid | Whole number | 10 |
if( "soort_code" = 'K', "aantal", 0) |
sum |
aantal_K | Whole number | 10 |
if( "soort_code" = 'G', "aantal", 0) |
sum |
aantal_G | Whole number | 10 |
if( "soort_code" = 'T', "aantal", 0) |
sum |
aantal_T | Whole number | 10 |
if( "soort_code" = 'S', "aantal", 0) |
sum |
aantal_S | Whole number | 10 |
Het ziet er als het goed is nu zo uit:
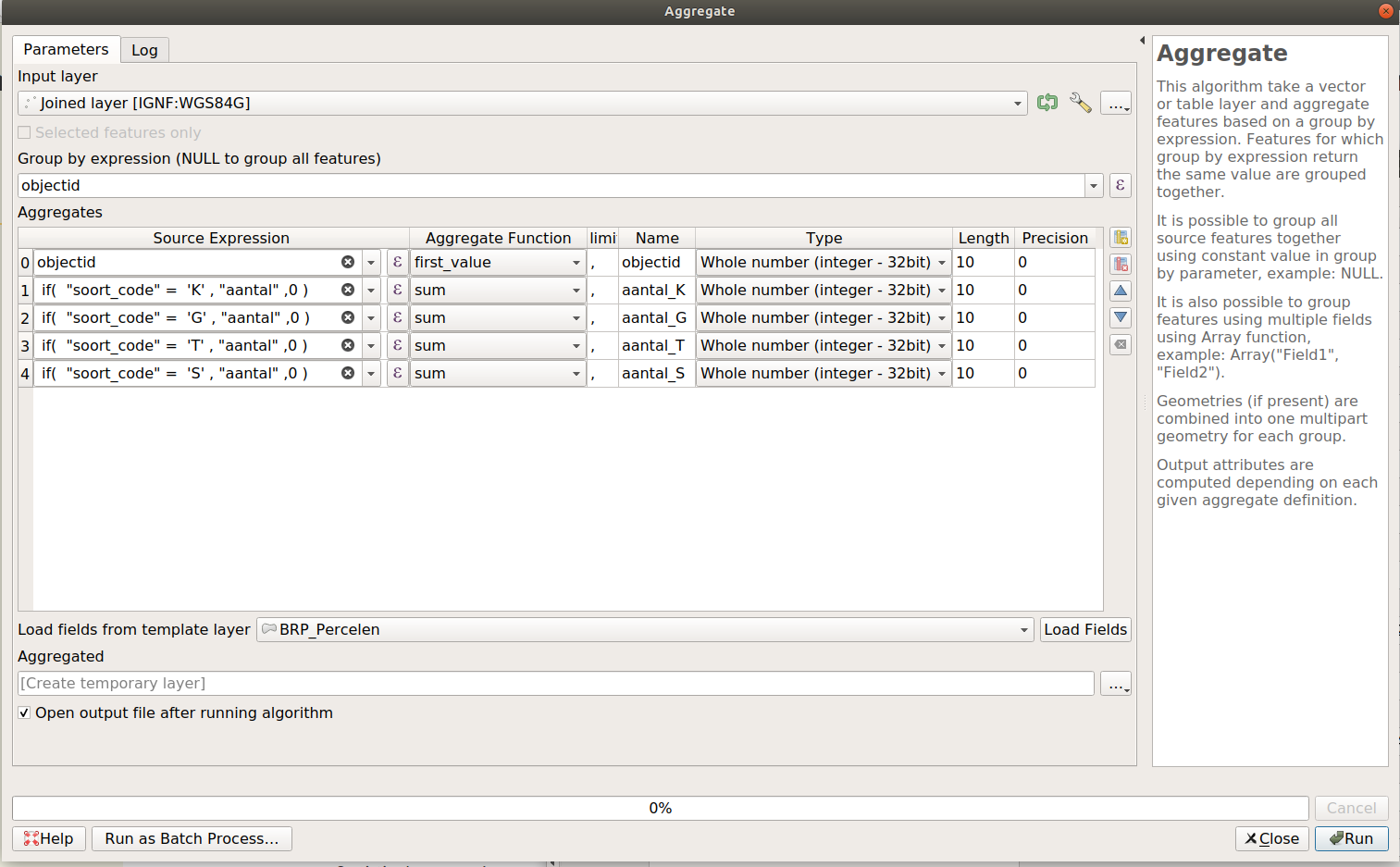
Run de tool
Onderzoek de tijdelijke aggregate laag die we nu hebben gemaakt. Open de attribuut tabel en klik op 1 record. Zie je dat er meerder punten worden geselecteerd? We hebben nu een multi-point geometry.
Join
De samengevoegde data kunnen we makkelijk koppelen met de bestaande percelen.
Rechtermuisklik op de BRP gewassen subset layer. Kies Properties
Ga naar het tabblad Joins
Voeg een nieuwe join toe door op de groene plus te klikken. Er opent zich een nieuw venster.
We willen de aggregatie tabel koppelen. Kies deze en zet de velden waarmee beide tabellen gekoppeld moeten worden op de juiste attributen. > objectid
Klik op OK
Bekijk de attribuut tabel van de BRP percelen. Is het gelukt?
Pas de stijling aan van de percelen zodat we het aantal Kievieten kunnen zien.
Exporteer attribuut data naar Excel
Een derde methode om tot onze eind data te komen zou kunnen zijn dat je de tabellen naar Excel exporteert, daar jouw magie vertoont, en dat de tabellen weer in Qgis terug zet! Waarom niet? We kunnen onze data namelijk makkelijk exporteren naar Excel.
Rechtermuis op de laag Percelen_beheer_vogels_totaal Export > Save Features As..
Kies MS Office open XML spreadsheet [XLSX] als data Format!
Onder Geometry zet deze op No Geometry
Geef het bestand een naam en locatie en sla het op.
Open het bestand in Excel om te zien wat je nu hebt.
Als je dit doet, let dan op, dat je altijd een objectid meeneemt waarmee je later weer de data terug kan koppelen aan de geometrien.
Let op! Het
fidveld is een automatisch gegenereerd, arbitrair veld, wat intern door Qgis(of een ander gis programma) wordt aangemaakt om unieke volg nummers te creëren. Gebruik deze echter nooit voor identificatie! Want het zegt niks over het perceel. De BRPobjectidis een administratieve code die samenhangt met de gewas informatie. Dit is de identificatie die je wilt gebruiken om veranderingen door de jaren heen te waarborgen.
Verwijderen lagen
Gooi alle tijdelijke lagen die je niet meer nodig hebt weg en sla alle eind resultaten netjes op in de 📂 werkfolder.
Rechtermuisklik op een tijdelijke laag > Remove Layer..
Als je dit doet op een tijdelijke laag dan wordt deze nergens meer bewaard. Als je dit doet op een bestaande laag, dan wordt deze uit het project verwijderd. De data staat nog steeds op de opgeslagen locatie.
Rechtermuisklik op een tijdelijke laag > Make Permanent. Sla deze op in de 📂 werkfolder.
Door naar
Sla je project een keer tussentijds op. Ctrl + s of Project > Save.
Ga nu door naar het volgende onderdeel > Qgis 3. - Maak je eigen data
You reached the end of this workshop!